GLC - Generalized Latent Correlation v. 1.0User Guide
John S. UebersaxFebruary 2008It is assumed the reader is already familiar with the tetrachoric correlation coefficient. If not, please see here: and here:The tetrachoric correlation coefficient estimates the correlation between two continuous variables/constructs based on dichotomous measures of these variables. That is, let x1 and x2 denote two dichotomous manifest variables. We assume these are dichotomized realizations of two underlying continuous variables, which we denote by y1 and y2. The tetrachoric correlation estimates, from x1 and x2 , what the correlation of y1 and y2 is.
Definitions:
A potential limitation of the tetrachoric correlation coefficient is that it assumes a bivariate normal distribution for y1 and y2. The glc program makes it possible to relax this assumption, providing a generalization of the tetrachoric correlation coefficient. For this, we make use of a convenient identity. The usual tetrachoric correlation coefficient model can be re-expressed as a latent trait model. The latter replaces the latent bivariate normal distribution of y1 and y2 with (1) a continuously distributed latent trait (θ), and (2) item response functions, one for each item. When the latent trait distribution is assumed Gaussian, and the item response functions are assumed to have the form of normal ogives (i.e., cdf's of normal distributions; this basically follows from the assumption of normally-distributed measurement error; Lord & Novick, 1968), then the latent trait model and tetrachoric correlation models produce identical results (Takane & de Leeuw, 1987). This correspondence gives us a way to relax the bivariate normality assumptions of the tetrachoric correlation model. Specifically, we may let the latent trait distribution have other distributional shapes -- including a skewed distribution.
Constructing a Skewed DistributionA skewed latent trait distribution is easily modeled as a mixture of two Gaussian distributions. That is the approach taken here. An arbitrary skewed distribution is produced by specifying the following parameters of a two-Gaussian mixture:
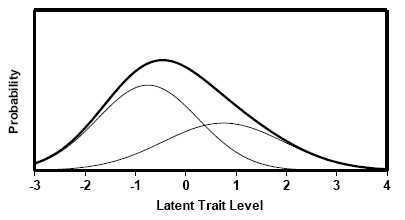 Figure 1. A skewed latent trait distribution modeled as a miture of two normal distributions. For 1., we need only specify the difference between the two means, as the location of the distributions on the x-axis is unimportant. These parameters are specified arbitrarily, according to ones prior judgment of how much skew the latent trait distribution has. (Note that for two binary items, there are no df available to estimate the amount of skew from the data themselves; any form of the latent trait distribution can be perfectly fitted to the data. For 3×3 or larger tables, the skew parameters can be estimated from the data using the LTMA program.) The glc program uses maximum likelihood estimation to estimate the correlation of the latent variables y1 and y2, or ρ(y1, y2), given the stipulated distribution parameters and the observed data. One might colloquially call this that skewed tetrachoric correlation or skewed latent correlation, but a more correct description would be the latent correlation assuming a skewed latent distribution. For simplicity, we could call this the generalized latent correlation and denote it as ρg.
Running the ProgramThe glc program runs in a Command Prompt (or DOS) window on Windows computers. Easy method. Navigate to the folder where glc.exe is, and click on the file icon. A command prompt window will open automatically as the program runs. After the program finishes, press the Enter key when prompted. Recommended method. A better approach is to manually open a command prompt window in the folder where the glc.exe program resides, and then to execute the command:
The command prompt window is very easy to use; for information, consult the help page here: After you start the program, many numbers may scroll in your command prompt window. That is normal. The more datasets you have, the longer this will take.When prompted, press the Enter key to terminate the program. Input FileThe input file contains run parameters and data. This file:
However, if you execute glc.exe from a different folder (which is possible in Command Prompt mode, but not recommended), then input.txt must be in your current folder. The safest solution is to always run glc.exe from your current folder. There is no problem making copies of glc.exe and placing one in your current working folder. The input file contains five command lines followed by data lines. The command lines are as follows:
Line 2. delta value. Difference between means of the component distributions. Line 3. sd(1). Standard deviation of the first component. Line 4. sd(2). Standard deviation of the second component. Line 5. r(2). Prevalence of the second component. On Lines 2-5 the numeric value must appear in the first 10 columns. Remaining columns can be used for comments. Note that only the prevalence of the second component, r(2), needs to be specified. The prevalence of the first component, r(1), is then determined by the requirement r(1) + r(2) = 1. The parameters sd(1) and sd(2) should almost always be set to 1.0. In any case, they mustn't be too much larger or smaller than 1.0 (e.g., within the range .5 to 2.0). That should be sufficient to model a wide range of skewed distributions. The Excel spreadsheet mixture.xls, will let you preview various combinations of mixing parameters, and shows a plot of the resulting distribution. Data Lines After the command lines come the data lines. The first data line specifies how many data sets you want to analyze. Following this, place on successive lines the data for each study to analyze. That is, each line contains the four frequencies of a 2×2 crossclassification table. Finally, after all datasets, place the command 'end' An example input file looks like this:
Example 1: Diagnostic agreement data (2-normal mixture)
1.000 DELTA Difference between means
1.000 SD1 Std dev 1
1.000 SD2 Std dev 2
.200 R1 Prevalence of class 2
3
144 72 8 15
100 15 17 23
211 12 43 75
end
Tetrachoric CorrelationsNote that you can use this program to estimate regular tetrachoric correlations. One just needs to specify a 0 separation between the means of the two component distributions. For example, you could use these values:
0.000 DELTA Difference between means
1.000 SD1 Std dev 1
1.000 SD2 Std dev 2
.500 R1 Prevalence of class 2
Output FileOutput is written to the file summary.txt. The file shows, for each dataset, the raw data, the chi-square fit value, and two parameters, r and rho(y1, y2). r is a parameter of the latent trait model; you may disregard it. What you want is rho(y1, y2): this is the latent correlation between your two variables. The value chisq should always be 0.00, meaning that the latent trait model was able to perfectly reproduce your observed data. If it is not 0, then there was a problem with the estimation algorithm; you are welcome to email me the data and summary.txt file to investigate. Data Exceptions Special cases in the data are treated as follows:
At present, standard errors of the latent correlations are not estimated. Potentially these could be added to the program, as the necessary information to compute them is already produced. Additional Output The file dist.csv gives the data for the latent trait distribution in a format suitable for plotting in Excel. Five columns are shown as follows: (a) the quadrature node index (not important); ( b) the latent trait abscissa value; (c) and (d) the densities of the two component distributions, and (e) the probability density of the marginal latent trait distribution. Ignore the values in row 102. The file output.txt contains estimation details on each dataset for which ML estimation was applied; this output is basically an artifact of the estimation engine, and you you can disregard it.
------------------------------------------------------------------ Disclaimer: CitationThe following may be used to cite the glc program:
References
Bock RD, Lieberman M. Fitting a response curve model for dichotomously scored items. Psychometrika, 1970, 35, 179-198. Lazarsfeld PF, Henry NW. Latent Structure Analysis, Boston: Houghton Mifflin, 1968. Lord FM, Novick MR. Statistical Theories of Mental Test Scores. Reading, Massachusetts: Addison-Wesley, 1968. Takane Y, de Leeuw J. On the relationship between item response theory and factor analysis of discretized variables. Psychometrika, 1987, 52, 393-408. Uebersax JS, Grove WM. A latent trait finite mixture model for the analysis of rating agreement. Biometrics, 1993, 49, 823-835. Go to Latent correlation with a skewed latent trait distribution Go to Tetrachoric and polychoric correlation page Go to Agreement Statistics Go to Latent Structure Analysis Last updated: 6 Febrary 2008 (c) 2008 John Uebersax PhD email |